Buffer Overflows
This note goes over buffer overflow vulnerabilities, and how exploits can be conducted using them. If you wish to go over security mechanisms to mitigate attacks using buffer overflows (aka dynamic protection), please check this note.
Buffer overflows are anomalies in computers, that happen when a program tries to write to a certain contiguous memory space (buffer) more data than the allocated data to that buffer (resulting in a buffer overflow).
But why are buffer overflows dangerous? Buffer overflows can happen accidentally (due to bugs), and its effects have no impact security-wise. However, an attacker can intentionally cause a buffer overflow, with the objective of running code with superuser privileges. An attacker can also use this to steal data (buffer overread in this case).
Cause
The cause for buffer overflows has to do with how the C/C++ languages work; these languages do not verify if data being written exceeds the capacity of a buffer/array/vector. Buffer overflows cannot be exploited in languages like Java/C#, as these languages do this type of verifications at runtime.
The problem, whilst being related with C/C++, is present in a set of vulnerable functions that should never be used, like:
- gets()
- strcpy()
- sprintf()
- scanf()
Defending against BOs
The solution against buffer overflows attacks is simple: always perform bounds checking. This can be done manually, or through replacing unsafe functions (the one above) by safe functions (these perform bounds checking).
Example: gets()
Wrong: Never use gets() !
char buf[1024];
gets (buf);
Right:
char buf [BUFSIZE];
fgets (buf, BUFSIZE, stdin);
Example: strcpy()
Solution 1:
if (strlen (src) >= dst_size) {
/* throw an error */
} else
strcpy (dst, src)
Solution 2:
strncpy (dst, src, dst_size - 1);
dst [dst_size - 1] = ‘\0’;
Solution 3:
dst = (char *) malloc (strlen(src) + 1);
strcpy (dst, src)
Stack Smashing
Stack smashing is the classical buffer overflow attack. Here is an example of code that is vulnerable to this attack:
void test(char *s) {
char buf[10]; // gcc stores extra space
strcpy(buf, s); // does not check buffer’s limit
printf("&s = %p\n&buf[0] = %p\n\n", &s, buf);
}
main(int argc, char **argv){
test(argv[1]);
}
Example Code 1: Stack Smashing vulnerable code
Here, strcpy simply copies the content of s into buf, without checking the length of s, which can lead to content being written after the allocated space for buf. These writes are used in stack smashing attacks, and the attacker can use this for several effects; to understand what can the attacker do, we first need to understand the stack layout.
Stack Layout
The following image depicts the general layout of the stack:
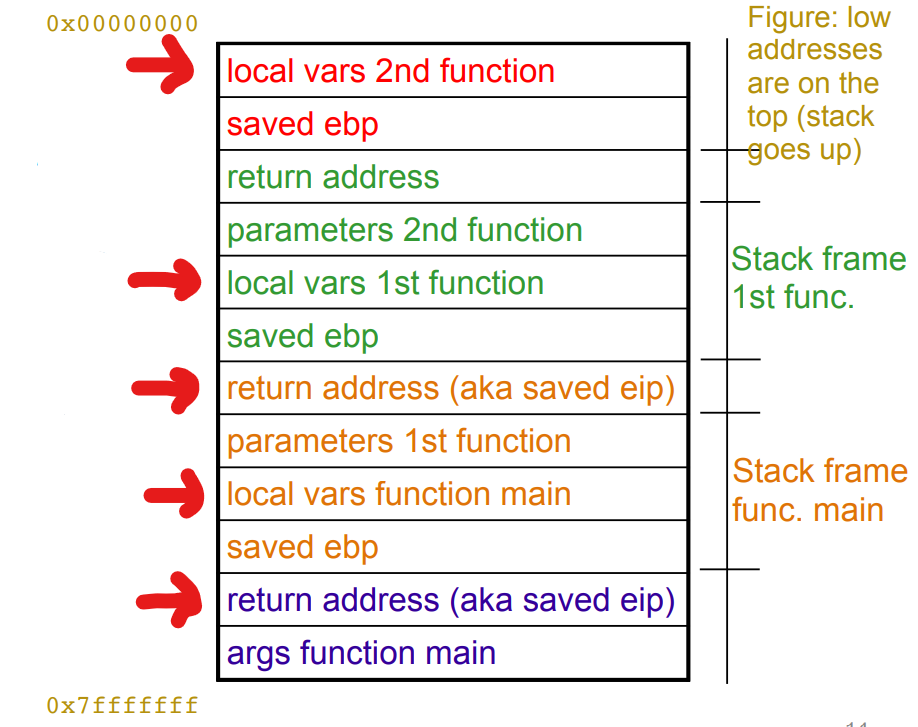
Fig.1: Stack Layout; the red arrows point to the "targets" of stack smashing attacks
In stack smashing attacks, the overflow can happen in two places:
- Local vars
- Saved EIP
The possible effects that this can have are:
- Change state of program
- Crash program
- Execute code
Now that we know the general layout of the stack, we will take a look at the assembly code of the code presented above (Example Code 1).
Stack Smashing Attack
test
push ebp
mov ebp,esp
sub esp,0x14 // allocate buffer
----------------------------------------------------- strcpy part
mov eax,DWORD PTR [ebp+0x8] // corresponds to the loading of s.
Notice that s is 8 chars below
the ebp (return address)
sub esp,0x8
push eax // add &s to stack
lea eax,[ebp-0x12] // corresponds to the loading of buf.
Notice that buf is 0x12 = 18 chars above
the ebp (return address)
push eax // add &buf to stack
call strcpy
-----------------------------------------------------
...
ret // jumps to return address
main:
...
call test
Notice how memory space for buf is allocated above the return address, and memory space of s is below return address. This is because of the stack layout presented in Fig.1: if you look at that figure, in the stack frame for the first function, we can see that local vars function is above the return address, and parameters function in the main stack frame (which is the case of s), is below the return address of 1st function.
There are a couple of important things we can take from this assembly code. In the first two lines we can see that we "save" the previous function's (main()) stack pointer in the ebp register. Then, we proceed to allocate 18 bytes for buf (right above the saved ebp and return address (saved eip)). Therefore, when we overflow buf, the first affected memory locations correspond to ebp and eip.
Up next is an image that makes this much clearer:
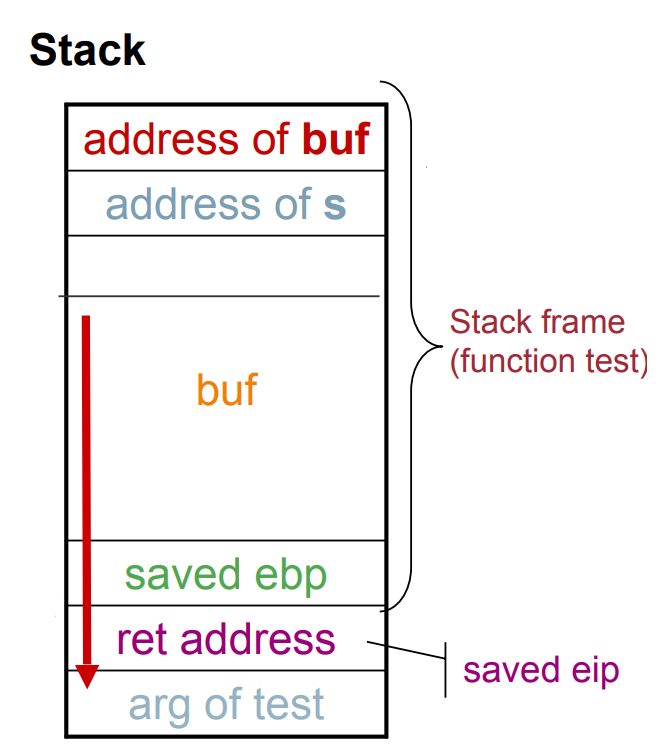
Fig.2: Location of variables in stack
From this we can take the following conclusion: by overflowing buf, we can alter the content of ebp, and potentially the return address of the function. But what is the purpose of changing the return address to an attacker? The answer is that, if the attacker provides the right input, he can effectively call other functions that wouldn't be called in the normal execution of the program, thus controlling the flow of the program.
Let's take a modified version of the Example Code 1:
void cannot(){
puts("This function cannot be executed!\n");
exit(0);
}
void test(char *s) {
char buf[10]; // gcc stores extra space
strcpy(buf, s); // does not check buffer’s limit
printf("&s = %p\n&buf[0] = %p\n\n", &s, buf);
}
main(int argc, char **argv){
printf("&cannot = %p\n", &cannot);
test(argv[1]);
}
The question is: are we able to call cannot() ? Here is what we are trying to achieve, in a shortened version of the assembly code of this program:
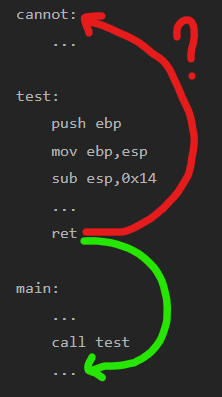
Fig.3: Can we call cannot?
To call cannot, we first need to know its address (can try to guess). If the address of cannot is, for example, 0x80484b6, we can successfully redirect the flow of the program with the following input:
b"x"*22 + b”\xb6\x84\x04\x08"
Here we assume we know the address, but in a real world scenario, how can an attacker know the address? It depends whether the attacker has access to the code:
- With the code: Analyze memory (gdb)
- Without the code: Trial and error
Code Injection
In the previous chapter we saw how we could use stack smashing to alter the control flow of a program; however, this is not the only thing we can do, as it is possible to inject shell code. To way we do this depends on the OS:
- In Unix, make program give a shell: /bin/sh
- In Windows, install rootkit/RAT
Code Injection in Unix
In Unix, the following code can span a shell:
char *args[] = {“/bin/sh”, NULL};
execve(“/bin/sh”, args, NULL};
This corresponds to the following assembly code:
xor %eax, %eax // %eax=0
movl %eax, %edx // %edx = envp = NULL
movl $address_of_bin_sh, %ebx //%ebx = /bin/sh
movl $address_of_argv, %ecx //%ecx = args
movl $0x0b, %al //syscall number for execve()
int $0x80 //do syscall
The last two lines serve the purpose of calling the execve syscall. System calls serve for several purposes; the execve syscall makes the OS launch a certain program, in this case a shell. There is more info about syscalls here.
Difficulties with Code Injection
Injecting code using vulnerable programs is not simple, as there are many difficulties/restraints with what an attacker can do. These are some of the main problems an attacker can encounter:
- Lack of space for code
- Forces attacker to reduce code
- Code may not include zeros/NULL bytes
- Some functions like strcpy() stop at the first
\0 - Substitute places with zeros by equivalent code:
- mov eax, 0 -> xor eax, eax
- Some functions like strcpy() stop at the first
- Difficulties discovering address where code is injected
- Stack has to be executable (usually is)
- If it isn't there are other ways to attack: next chapter
Return to libc
One other way to exploit buffer overflows is through inserting a new arc in the control flow graph of the program (arc is simply another node in the graph). This means inserting a new call to a function in the program, but this time from the libc library (C standard library), and typically to the system() function of libc.
This type of attack is effective against non-executable stacks, because it calls a function of libc, which doesn't belong to the stack. Also, the system() function executes anything that it is passed to it, making it a good candidate for these types of attacks
The following code is an example of the attack using this (R should contain the address of attacker supplied data):
void system(char *arg){
check_validity(arg); //bypass this
R=arg;
}
target: execl(R, …); //target is usually fixed
Pointer Subterfuge
So far we have seen two types of exploits with buffer overflows: code injection and return address alteration. But there is another effect we can achieve with buffer overflows: pointer modification; these types of exploits go by the name of pointer subterfuge, and there are several types:
- Function-pointer clobbering
- Modify a function pointer to point to attacker supplied code
- Data-pointer modification
- Modify address used to assign data
- Exception-handler hijacking
- Modify pointer to an exception handler function
- Virtual pointer smashing
- Modify the C++ virtual function table associated with a class
Function-pointer clobbering
Function-pointer clobbering aims at changing a function's pointer, to point to the code desired by the attacker (usually this malicious code is provided by the attacker). Here is a code example:
void f2a(void * arg, size_t len) {
void (*f)() = ...; /* function pointer */
char buff[100];
memcpy(buff, arg, len); /* buffer overflow! We want to overwrite f with
address of malicious code in buff*/
f(); /* call function f*/
return;
}
Here is a diagram of what the stack will look like in this program:

Fig.4: Example of stack of code above
As we can see, if we overflow buff, the first memory chunks being affected are the chunks belonging to f. We can then change the address of f arbitrarily, and make it point to a desired location (maybe code present in buff, variable that is controlled by the attacker).
This type of attack combines well with arc injection/return to libc (make f point to system)
Data-pointer modification
In data-pointer modification, the attacker aims at changing a pointer used to assign a value, with the objective of making arbitrary memory writes. Up next is some example code:
void f2b(void * arg, size_t len) {
long val = ...;
long *ptr = ...;
char buff[100];
extern void (*f)();
memcpy(buff, arg, len); /* buffer overflow! */
*ptr = val; /* A buffer overflow in buff can overwrite
ptr and val, allowing us to write 4 bytes
of arbitrary values to the memory*/
f(); /* ... */
return;
}
Exception-handler hijacking
This next type of pointer subterfuge is possible in Windows OS, but to understand it we need to understand how Windows handles exceptions.
Windows keeps exception handlers in a linked list, called Windows Structured Exception Handler (SEH). When an exception occurs, the OS will iterate over this linked list; when it finds the correct exception handler corresponding to that exception, it will call that exception handler.
The important thing to note is that SEH is stored in the stack (and therefore vulnerable to buffer overflow attacks). A typical attack would:
- Change entries of SEH to point to attacker's malicious code, or to libc
- Generate an exception (e.g., an exception is generated when stack base pointer is overwritten)
To prevent this, validity and integrity checking of SEH were introduced in Windows.
Virtual pointer smashing
Virtual pointer smashing takes advantage of a characteristic of the C++ language: most C++ compilers keep the functions of each class in a virtual function table (VTBL). This table is simply an array of function pointers, pointing to the functions corresponding to the methods of a certain class (there is a VTBL for each different class).
To access a VTBL, each object keeps a virtual table pointer (VPTR) to the its class VTBL. The attack simply consists in altering the VPTR, to point to supplied code by the attacker, or to libc (similar to attacks we have seen previously).
Here is a snippet of code vulnerable to this type of attack:
void f4(void * arg, size_t len) {
C *ptr = new C;
char *buff = new char[100];
memcpy(buff, arg, len); // buffer overflow!
ptr -> vf(); // call to a virtual function
return;
}
Off-by-one errors
The main way to prevent buffer overflows is through bounds checking. However, we still need to be careful to not make mistakes while performing bounds checking. Let's take a look at the following code snippet:
int get_user(char *user) {
char buf[1024];
if (strlen(user) > sizeof(buf))
handle_error (“string too long”);
strcpy(buf, user);
}
All seems well with this code: before calling strcpy, we check if the length of the provided user string is greater than the size of the buf variable. However, there is a mistake in this code: sizeof(buf) always return 1024, but the user might provide a string of 1024 chars plus a '\0' in the end, making strlen(user) return 1024 (strlen doesn't count the '\0'), which means that the if statement returns true, but strcpy will in fact copy 1025 bytes into buf, overflowing 1 byte. These types of overflows are called off-by-one errors.
But what is the possible harm caused by overflowing just one byte? To understand this we need to remind ourselves of the stack layout:
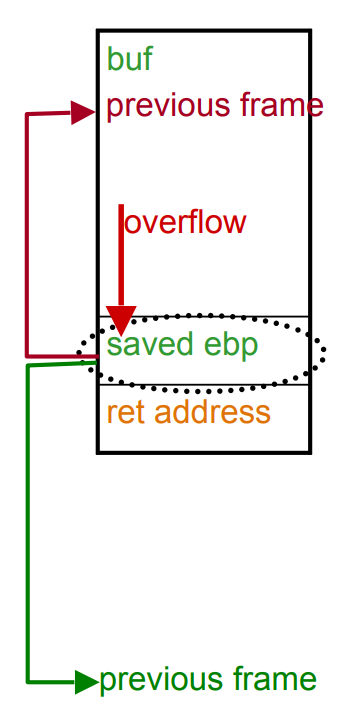
Fig.5: Stack layout
As we can see, the address immediately after buf corresponds to the saved ebp (base pointer). If we consider that the saved ebp's length is 4 bytes, if the attacker sets the last char of the provided string equal to 0, then he is setting the most significant byte of ebp equal to 0. This means that ebp is reduced by 0 to 255 bytes. This makes the saved ebp point to a different location, and the attacker is able to change local variables/return address (like it is shown in Fig.5).
Return-Oriented Programming Attacks
The return to libc attacks we saw previously have a major impracticality to use as an exploit: they don't work well in 64-bit CPUs (because parameters of 1st function are put in registers). An alternative to this is return-oriented programming (ROP).
In ROP attacks, we analyze assembly code looking for ret calls (in machine code, c3). The sequence of instructions preceded by ret are called gadgets.
Sequence of instructions ending with ret
Gadgets might not necessarily be included in the original code: we just need to find c3 instructions. Here is an example of this:
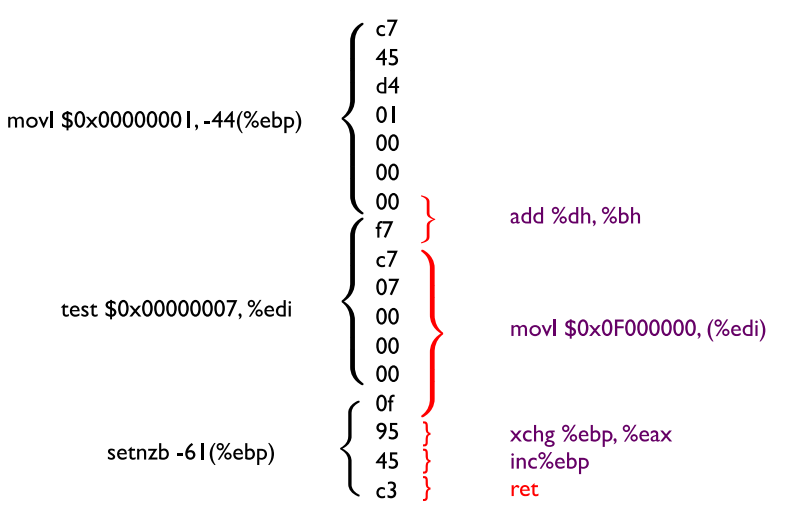
Fig.6: ret example
The job of an attacker in return-oriented programming attacks is to analyze binary code, find instructions sequences ending in c3 (gadgets), and collect the addresses of these gadgets. Finally, to run the attack the attacker should:
- Overflow the stack with addresses of gadgets
- Overflow the stack with other data the gadgets may pick from the stack
Here is an example of this:
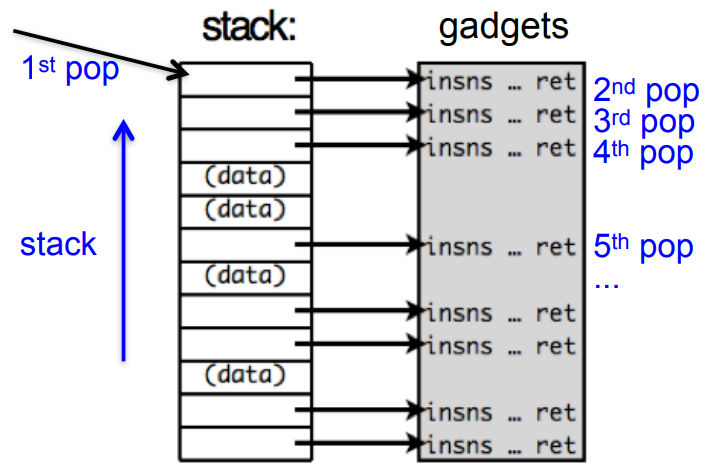
Fig.7: Example of a diagram of a return-oriented programming attack
Integer Overflows
Integer overflows are often related to the improper assignment of the several data types that can be used to represent integers (signed vs unsigned, long vs short, etc.). Integer semantics are often complex, and programmers don't fully know all the details, which can lead to problems in several languages (but especially C/C++). The 4 possible problems that can occur from assigning different types of integer types are:
- Overflow
- Underflow
- Signedness error
- Truncation
These problems can lead to 5 possible exploits:
- Insufficient memory allocation -> BO -> attacker code execution
- Excessive memory allocation/infinite loop -> denial of service
- Attack against array byte index -> overwrite arbitrary byte in memory
- Attack to bypass sanitization -> cause a BO -> ...
- Logic errors (e.g., modify variable to change program behaviour)
We will now take a closer look at each of the problems described above.
Overflow
Overflow problem is the most common integer overflow form, and it happens when the result of an expression exceeds the maximum value used by a certain data type (e.g., max size of int is 2147483647).
Let's take a closer look at this code example:
void vulnerable(char *matrix, size_t x, size_t y, char val){
int i, j;
matrix = (char *) malloc (x*y);
for (i=0; i < x; i++){
for(j = 0; j < y; j++){
matrix[i*y+j] = val;
}
}
}
The problem with this code is that if x * y > MAXINT, then malloc doesn't reserve enough memory.
Underflow
Underflow are usually related to subtractions of unsigned types, e.g. subtracting and storing the result in a unsigned int. This problem is rarer than overflow, as it only happens with subtraction.
Here is a real-world example (Netscape JPEG comment length vulnerability):
void vulnerable(char *src, size_t len){
size_t real_len;
char *dst;
if (len < MAX_SIZE) {
real_len = len - 1;
dst = (char *) malloc(real_len);
memcpy(dst, src, real_len);
}
/* if len = 0
then real_len = FFFFFFFF
malloc allocs FFFFFFFF bytes */
}
Signedness Error
In these cases what happens is a signed integer is assigned to an unsigned variable, or vice-versa. One example of what can result from this is if a positive unsigned integer is assigned to a signed integer variable; if the number being assigned is larger than , this means that the most significant bit is 1, and therefore a signed variable will interpret it as negative.
The following example illustrates this:
void vuln(char *src, size_t len){
int real_len;
char *dst;
if (len > 1) {
real_len = len - 1;
if (real_len < MAX_SIZE) {
dst=(char *) malloc(real_len);
memcpy(dst, src, real_len);
}
}
} /* line 5 is negative if len > 2^(31)
Truncation
This error happens when we assign a value of data type that can hold numbers of greater lengths to a data type that can hold smaller lengths (e.g, assign long to short). This can lead to unauthorized writes to memory.
Take a look at the following example:
void vuln(char *src, unsigned len) {
unsigned short real_len;
char *dst;
real_len = len;
if (real_len < MAX_SIZE) {
dst = (char *)malloc(real_len);
strcpy(dst, src);
}
}
The problem with this code is that the value in real_len might become become truncated, leading to insufficient memory being allocated by malloc. Because of this, dst might not have enough memory allocated to it, leading to strcpy overwriting memory after dst.
Heap Overflows
So far we have only seen overflows that affect memory in the stack. However, as one can imagine, an attacker can also take advantage of buffer overflows to influence data in the heap.
Let's take a look at the following code example:
main(int argc, char **argv) {
int i;
char *str = (char *)malloc(4);
char *critical = (char *)malloc(9);
strcpy(critical, "secret");
strcpy(str, argv[1]);
printf("%s\n", critical);
}
The heap resultant of this program would look something like this:

Fig.8: Variables str and critical_ allocated in the heap
Let's say we created a program that analyzes the memory and prints the content of each memory position, starting in str and ending in the end of memory allocated to critical (you can find this code here). If we provided as input the string "xyz" to the program above , the resulting memory content would be this:
Address of str is: 0x80497e0
Address of critical is: 0x80497f0
0x80497e0: x (0x78)
0x80497e1: y (0x79)
0x80497e2: z (0x7a)
0x80497e3: ? (0x0)
0x80497e4: ? (0x0)
0x80497e5: ? (0x0)
0x80497e6: ? (0x0)
0x80497e7: ? (0x0)
0x80497e8: ? (0x0)
0x80497e9: ? (0x0)
0x80497ea: ? (0x0)
0x80497eb: ? (0x0)
0x80497ec: ? (0x11)
0x80497ed: ? (0x0)
0x80497ee: ? (0x0)
0x80497ef: ? (0x0)
0x80497f0: s (0x73)
0x80497f1: e (0x65)
0x80497f2: c (0x63)
0x80497f3: r (0x72)
0x80497f4: e (0x65)
0x80497f5: t (0x74)
0x80497f6: ? (0x0)
0x80497f7: ? (0x0)
0x80497f8: ? (0x0)
However, if we take a look at the code, we can see that bounds checking is not performed on the string given by the user, and therefore the second strcpy can cause a buffer overflow. If that overflow is long enough, we can change the value of critical.
To do this, we can run the code with the following input: "xyz1234567890123FooBar". If we run our memory printing program, we get the following output:
Address of str is: 0x80497e0
Address of critical is: 0x80497f0
0x80497e0: x (0x78)
0x80497e1: y (0x79)
0x80497e2: z (0x7a)
0x80497e3: 1 (0x0)
0x80497e4: 2 (0x0)
0x80497e5: 3 (0x0)
0x80497e6: 4 (0x0)
0x80497e7: 5 (0x0)
0x80497e8: 6 (0x0)
0x80497e9: 7 (0x0)
0x80497ea: 8 (0x0)
0x80497eb: 9 (0x0)
0x80497ec: 0 (0x11)
0x80497ed: 1 (0x0)
0x80497ee: 2 (0x0)
0x80497ef: 3 (0x0)
0x80497f0: F (0x73)
0x80497f1: o (0x65)
0x80497f2: o (0x63)
0x80497f3: B (0x72)
0x80497f4: a (0x65)
0x80497f5: r (0x74)
0x80497f6: ? (0x0)
0x80497f7: ? (0x0)
0x80497f8: ? (0x0)Additional Content
Syscall Table
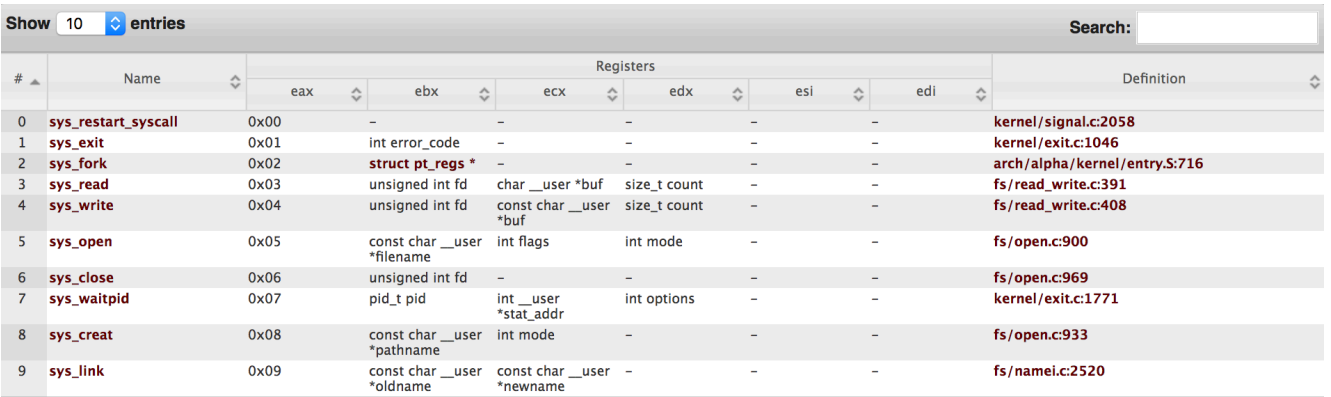
Fig.9: Table with some of Linux's syscalls
Code to Write Memory Content
main(int argc, char **argv) {
int i;
char *str = (char *)malloc(4);
char *critical = (char *)malloc(9);
char *tmp;
printf("Address of str is: %p\n", str);
printf("Address of critical is: %p\n", critical);
strcpy(critical, "secret");
strcpy(str, argv[1]);
tmp = str;
while(tmp < critical + 9) { // print heap content
printf("%p: %c (0x%x)\n",
tmp, isprint(*tmp) ? *tmp: '?', (unsigned)(*tmp));
tmp += 1;
}
printf("%s\n", critical);
}